해당 포스트는 KT olleh ucloud biz의 지원을 받고 작성되었습니다.
지난주에도 살짝 언급하기는 했지만, 지난 번의 아키텍처는 사실 분산이 어려운 구조입니다. 하나의 서버안에 웹서버와 Celery가 함께 있어야만 데이터에 접근이 가능합니다. 즉 하나의 서버에서 남는 자원을 활용하는 형태가 되겠죠. 다음과 같은 형태입니다.

그러나 이러라고 만들어진 Celery가 아닌데, 과연 그렇다면 어떤 방법이 있을까요?
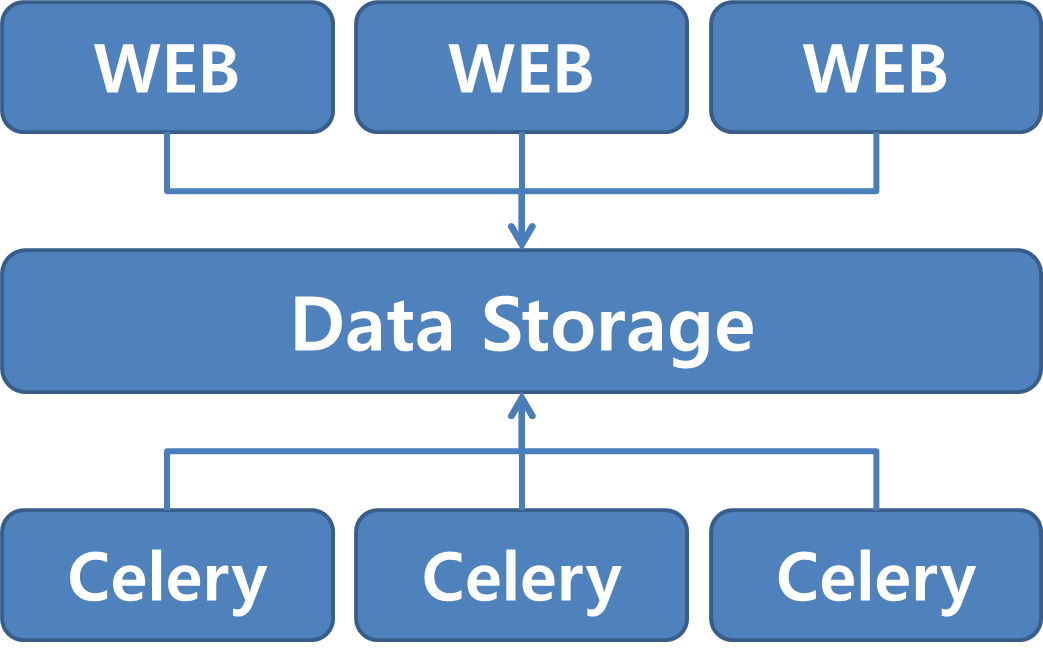
그런데 이런 고민이 사실 확장 가능한 시스템을 고민할 때 항상 하게 되는 고민입니다. 특히 현재의 일반적인 클라우드 서비스의 구조가 뒷단의 데이터 스토리지 영역에서 데이터를 동기화거나 저장해두고, 앞단에서는 공통적으로 이 데이터를 사용하자라는 개념으로 접근하게 됩니다. 즉, 다음과 같은 구조가 됩니다.

그런 연고로, 확장성을 위해서는 아래의 Data Storage Layer도 분산 시스템이 되어야 합니다. 그럼 다시 문제를 한정시켜서, 문자 추출 서비스를 할 때 여러 서버가 동시에 접근할 수 있는 파일 서비스가 필요합니다.
이럴 때 쉽게 사용할 수 있는것이 Object Store 이고 여기에 가장 유명한 것이 아마존의 S3입니다. 수 많은 기업들이 아마존 S3를 이용해서 서비스를 만드는 경우도 많습니다. 대표적인 케이스가 Dropbox 입니다. 물론, 여기서는 싱크를 잘 맞추는 게 더 어렵겠지만, 파일의 관리를 S3를 통해서 간소화 시켰습니다. 더 핵심에 집중하게 된거죠.
여기서도 마찬가지입니다. 텍스트 추출과 확장성이 목표라면, 이런 서비스를 안 쓸 이유가 없겠죠. KT ucloud 에서 제공하는 ucloud storage 는 기본적으로 openstack의 swift 서비스를 사용중입니다.
사용을 위해서는 다음과 같이 해당 페이지에서 API Key를 받아야 사용이 가능합니다.

그렇다면 이제 어떻게 아키텍처가 변경이 되게 될까요? 웹 서버는 swift나 S3 같은 곳에 등록된 파일을 저장하게 됩니다. 그리고 그쪽 파일 uri를 celery에 전달하게 되면, celery는 자신의 local이 아닌 분산 오브젝트 스토어에서 해당 파일을 읽고 이를 읽어서 처리하게 되는 것입니다.
다음과 같이 중간의 Data Storage가 하나라면 SPOF가 되지만, 분산 파일 시스템이라면, 장애에 안정적이고 확장성도 높아지는 아키텍처가 구성이 되는 것입니다.
물론, 장단점이 다 존재합니다. 추가적인 레이어를 사용하기 위해서 각각 네트웍을 통해서 파일을 쓰고 읽는 과정이 필요합니다. 이제 여기서 고민할 것은 각각의 비용이 얼마나 쌀지 생각해서 비용이 더 싼 곳으로 결정하는 지혜(?)가 필요합니다.(이건 뭐, 알아서 ㅎㅎㅎ)
여기에서 추가로 더 확장을 한다고 하면, 각각의 클라우드 서비스가 제공하는 API를 이용해서 자동으로 장비를 부하에 따라서 확장을 하는 것도 가능합니다.
ucloud storage 나 S3 말고도, 직접 ceph 나 grusterfs를 설치해서 직접 관리하는 방법도 있습니다.
여러가지 말들을 주절주절 적었지만, 결론은, 자신의 요구사항에 맞는 형태에서 가장 효과적인 아키텍처를 고민해야 한다는 것입니다. 특히 클라우드의 특성을 잘 알아야 안정적인 서비스를 구축할 수 있습니다. 특히 클라우드로 넘어가면서 속도보다는 안정성/확장성을 더 높이는 방향으로 설계를 하는 것이 클라우드 환경에서는 유리합니다.
ps. python으로 swift 관련 작업을 한다면, 다음 문서를 참고해서 swift-tool을 사용해보는 것도 좋습니다.(http://developer.ucloudbiz.olleh.com/blog/swift/ucloud-storage—Swift-Tool/)





