이때 기본적으로 ngx_stream_module.so 이 load 가 되어 있지 않기 때문에 load_module 로 해당 모듈을 등록해줘야만 stream 키워드가 사용가능하다. 이때 위에 yum 으로 설치한 경로와 기본 경로가 다를 수 있으므로 해당 경로에 링크를 걸어주거나 아래와 같이 절대 경로를 적어줘야 한다.
위의 링크를 잘 읽어보면 인증 정보 만들기에서 OAuth 클라이언트 ID로 만들어진 경우이다. 그런데, python 등에서 사용하다보면 보통 ServiceAccount 를 이용하는 형태를 스게 되는데, 이 두가지가 서로 달라서 위의 샘플로 ServiceAccount 형태의 인증을 요청하면 InvalidArgumentException을 만나게 된다.
위의 링크에서 전자(OAuth 클라이언트ID)의 방식을 잘 설명하고 있으므로 여기서는 후자만 다룬다.
접속 방법
간단한 접속 코드는 다음과 같다. (GoogleCredential 이 그런데 deprecated 되는 건 함정)
import com.google.api.client.auth.oauth2.Credential
import com.google.api.client.googleapis.auth.oauth2.GoogleClientSecrets
import com.google.api.client.googleapis.auth.oauth2.GoogleCredential
import com.google.api.client.googleapis.javanet.GoogleNetHttpTransport
import com.google.api.client.json.gson.GsonFactory
import com.google.api.services.sheets.v4.Sheets
import com.google.api.services.sheets.v4.SheetsScopes
import org.springframework.context.annotation.Configuration
import java.io.IOException
import java.security.GeneralSecurityException
import java.util.*
@Configuration
class GoogleAuthorizationConfig {
private val applicationName: String = "test-api"
private val credentialsFilePath: String = "/credentials.json"
private val tokensDirectoryPath: String = "tokens"
@Throws(IOException::class, GeneralSecurityException::class)
private fun authorize(): Credential {
val inputStream = GoogleAuthorizationConfig::class.java.getResourceAsStream(credentialsFilePath)
val googleCredential = GoogleCredential.fromStream(inputStream)
.createScoped(Collections.singleton(SheetsScopes.SPREADSHEETS_READONLY))
return googleCredential
}
@get:Throws(IOException::class, GeneralSecurityException::class)
val sheetsService: Sheets
get() {
val credential: Credential = authorize()
return Sheets.Builder(
GoogleNetHttpTransport.newTrustedTransport(),
JSON_FACTORY, credential
)
.setApplicationName(applicationName)
.build()
}
companion object {
private val JSON_FACTORY: com.google.api.client.json.JsonFactory = GsonFactory.getDefaultInstance();
}
}
그리고 이제 각 sheet 정보와 각각의 데이터를 가져오는 걸 알아보자.
fun getSpreadSheets(page: String) {
val sheetsService = googleAuthorizationConfig.sheetsService
val sheets = sheetsService.spreadsheets().get(page).execute()
sheets.sheets.map {
println(it.properties.title)
val sheet = sheetsService.spreadsheets().values().get(page, it.properties.title).execute()
val values = sheet.getValues()
values.map { //row 별로 가져오는 코드
it.map { // 각 라인의 컬럼별로 가져오는 코드
print(it)
print(",")
}
println("-----")
}
}
}
그냥 아주 간단한 내용입니다. 해당 날짜의 시작시간과 끝 시간을 만들고 싶을때가 있는데. LocalDate 를 쓰면 asStartOfDay 라는 메서드를 통해서 쉽게 시작 시간을 구할 수 있습니다.
import java.time.LocalDate;
import java.time.LocalDateTime;
public class Main {
public static void main(String[] args) {
LocalDate a = LocalDate.of(2014, 6, 30);
LocalDateTime l = a.atStartOfDay();
System.out.println(l);
}
}
그런데 끝 시간을 구하는 건 애매하고, 또한 LocalDateTime 이 아니라 LocalDate 에서 구하는 거라 귀찮습니다.(그러나 이 블로깅을 하면서… 아주 많은 방법이 있다는 것을 알고 여기서… 접어야…)
com.amazonaws.services.s3.model.AmazonS3Exception: The provided token has expired. (Service: Amazon S3; Status Code: 400; Error Code: ExpiredToken; Request ID: 0NV9YTKYVBCEPCB1; S3 Extended Request ID: TYjnvp4WwoLNm/Eytu+qXleNLFYDYbc7jyr7yt2x8jSGkGG5w0/f8D2TJGgQWNmRCRIwB3ahiZI=; Proxy: null)
그런데 이상한 것은 해당 서버는 Instance Profile 이 연결되어 있어서, 제대로 서버내에서 터미널에서는 S3에 계속 접근이 잘 되는 상황이었습니다. 그런데 계속 TokenExpire 가 발생해서 이상하다고 생각하고 검색을 하다보니, 아래와 같이 도움되는 블로그를 찾게되었습니다.
굉장히 도움이 되었던 내용은 InstanceProfileCredentialsProvider를 이용하는데, 이게 Expire 가 설정되어 있어서 중간에 만료가 될 수 있다는 부분이었습니다. 그리고 거기에 보면 직접 Instance를 넘기면 토큰이 자동으로 Refresh 가 된다라는 얘기였습니다.
그런데 그러면 언제 토큰이 Refresh 가 될까요? InstanceProfileCredentialsProvider 안에는 refresh 함수가 있습니다. 그런데 이 refresh는 기본적으로는 handleError 가 발생하면 호출이됩니다.
public class InstanceProfileCredentialsProvider implements AWSCredentialsProvider, Closeable {
......
private void handleError(Throwable t) {
refresh();
LOG.error(t.getMessage(), t);
}
......
@Override
public void refresh() {
if (credentialsFetcher != null) {
credentialsFetcher.refresh();
}
}
......
}
그리고 이 refresh 함수는 BaseCredentialsFetcher 안에서 영향을 줍니다. 아래 코드와 같이 refresh 를 하면 credentials 가 null이 되어서 needsToLoadCredentials 에서 true를 리턴하게 되므로, getCredentials를 하면 fetchCredentials() 를 호출해서 credential을 다시 가져오게 됩니다.
@SdkInternalApi
abstract class BaseCredentialsFetcher {
public AWSCredentials getCredentials() {
if (needsToLoadCredentials())
fetchCredentials();
if (expired()) {
throw new SdkClientException(
"The credentials received have been expired");
}
return credentials;
}
boolean needsToLoadCredentials() {
if (credentials == null) return true;
if (credentialsExpiration != null) {
if (isWithinExpirationThreshold()) return true;
}
if (lastInstanceProfileCheck != null) {
if (isPastRefreshThreshold()) return true;
}
return false;
}
public void refresh() {
credentials = null;
}
}
그런데 위의 getCredentials() 가 호출이 되어야만 하는데, 저게 언제 되는지는 알 수가 없습니다.
그래서 단순히 해당 블로그의 InstanceProfileCredentialsProvider.getInstance()를 호출하면 좀 이슈가 있을 수 있습니다. 그런데 InstanceProfileCredentialsProvider는 하나의 생성 method를 제공하는데 다음과 같습니다.
public class InstanceProfileCredentialsProvider implements AWSCredentialsProvider, Closeable {
public InstanceProfileCredentialsProvider(boolean refreshCredentialsAsync) {
this(refreshCredentialsAsync, true);
}
private InstanceProfileCredentialsProvider(boolean refreshCredentialsAsync, final boolean eagerlyRefreshCredentialsAsync) {
credentialsFetcher = new InstanceMetadataServiceCredentialsFetcher();
if (!SDKGlobalConfiguration.isEc2MetadataDisabled()) {
if (refreshCredentialsAsync) {
executor = Executors.newScheduledThreadPool(1, new ThreadFactory() {
public Thread newThread(Runnable r) {
Thread t = Executors.defaultThreadFactory().newThread(r);
t.setName("instance-profile-credentials-refresh");
t.setDaemon(true);
return t;
}
});
executor.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
try {
if (shouldRefresh) credentialsFetcher.getCredentials();
} catch (AmazonClientException ace) {
handleError(ace);
} catch (RuntimeException re) {
handleError(re);
}
}
}, 0, ASYNC_REFRESH_INTERVAL_TIME_MINUTES, TimeUnit.MINUTES);
}
}
}
}
refreshCredentialsAsync 가 true 가 넘어가면 Async 스레드가 생성되고 해당 비동기 스레드에서 ASYNC_REFRESH_INTERVAL_TIME_MINUTES 마다 getCredentials 를 호출해서 계속 Token을 재설정하게 됩니다.
이게 왜 문제가 되느냐? AWS를 쓰다보면 여러 이유로 멀티 Account 를 사용하게 되고, 이러면 다른 계정에서 특정 계정의 Bucket을 읽거나 써야하는 경우가 생깁니다. 다른 계정에서 읽어만 가는 경우는 큰 문제가 없는데, 다른 계정에서 해당 Bucket 에 쓰기를 하는 순간 권한 이슈가 발생하게 됩니다.
흔하게 다른 계정에서 스면, 해당 오브젝트의 권한이 생성자의 권한이 되버려서 정작 해당 버킷 소유자가 해당 오브젝트를 읽을 수 가 없습니다. 이런 걸 방지하는 것이 BucketOWnerFullControl 이거나 이제는 그냥 ACL을 끄고 Bucket Owner Enforced 를 쓰는 것입니다. 즉, 누가 쓰든 다 버킷 소유자의 것이다 라는 것이죠.
최근에 또 지인에게서 Redis Expire 관련 이야기가 나와서 다시 한번 살짝 정리해 보기로 합니다.
Redis 에서는 Expire라는 기능이 있어서 해당 Key의 수명을 지정해줄 수 있습니다. 그래서 수명이 지난 Key는 자동으로 사라지게 됩니다. 이를 이용하면, 실제로 필요없는 Key를 계속 관리할 필요가 없어집니다. 그런데 실제로는 이 메모리 해제가 쉽게 일어나지 않습니다. 이것은 기본적으로 Expire 가 된 메모리가 해제되는 시점이 3가지 경우가 있기 때문입니다.
Expire 기간이 지난 Key에 Access 하는 경우
명령을 수행하지 않고 이벤트가 발생하는 Tick 마다 적당량씩 삭제한다.
메모리가 부족할 때 메모리 정책에 따라서 메모리가 확보될때 까지 삭제한다.
먼저 첫번째 경우를 확인해보겠습니다.(Expire 기간이 지난 Key에 Access 하는 경우)
다음은 레디스에서 Key에 접근할 때 사용하는 lookupKey 함수입니다.
/* Lookup a key for read or write operations, or return NULL if the key is not
* found in the specified DB. This function implements the functionality of
* lookupKeyRead(), lookupKeyWrite() and their ...WithFlags() variants.
*
* Side-effects of calling this function:
*
* 1. A key gets expired if it reached it's TTL.
* 2. The key's last access time is updated.
* 3. The global keys hits/misses stats are updated (reported in INFO).
* 4. If keyspace notifications are enabled, a "keymiss" notification is fired.
*
* Flags change the behavior of this command:
*
* LOOKUP_NONE (or zero): No special flags are passed.
* LOOKUP_NOTOUCH: Don't alter the last access time of the key.
* LOOKUP_NONOTIFY: Don't trigger keyspace event on key miss.
* LOOKUP_NOSTATS: Don't increment key hits/misses counters.
* LOOKUP_WRITE: Prepare the key for writing (delete expired keys even on
* replicas, use separate keyspace stats and events (TODO)).
* LOOKUP_NOEXPIRE: Perform expiration check, but avoid deleting the key,
* so that we don't have to propagate the deletion.
*
* Note: this function also returns NULL if the key is logically expired but
* still existing, in case this is a replica and the LOOKUP_WRITE is not set.
* Even if the key expiry is master-driven, we can correctly report a key is
* expired on replicas even if the master is lagging expiring our key via DELs
* in the replication link. */
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
robj *val = NULL;
if (de) {
val = dictGetVal(de);
/* Forcing deletion of expired keys on a replica makes the replica
* inconsistent with the master. We forbid it on readonly replicas, but
* we have to allow it on writable replicas to make write commands
* behave consistently.
*
* It's possible that the WRITE flag is set even during a readonly
* command, since the command may trigger events that cause modules to
* perform additional writes. */
int is_ro_replica = server.masterhost && server.repl_slave_ro;
int expire_flags = 0;
if (flags & LOOKUP_WRITE && !is_ro_replica)
expire_flags |= EXPIRE_FORCE_DELETE_EXPIRED;
if (flags & LOOKUP_NOEXPIRE)
expire_flags |= EXPIRE_AVOID_DELETE_EXPIRED;
if (expireIfNeeded(db, key, expire_flags)) {
/* The key is no longer valid. */
val = NULL;
}
}
if (val) {
/* Update the access time for the ageing algorithm.
* Don't do it if we have a saving child, as this will trigger
* a copy on write madness. */
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
val->lru = LRU_CLOCK();
}
}
if (!(flags & (LOOKUP_NOSTATS | LOOKUP_WRITE)))
server.stat_keyspace_hits++;
/* TODO: Use separate hits stats for WRITE */
} else {
if (!(flags & (LOOKUP_NONOTIFY | LOOKUP_WRITE)))
notifyKeyspaceEvent(NOTIFY_KEY_MISS, "keymiss", key, db->id);
if (!(flags & (LOOKUP_NOSTATS | LOOKUP_WRITE)))
server.stat_keyspace_misses++;
/* TODO: Use separate misses stats and notify event for WRITE */
}
return val;
}
코드 중간에 expireIfNeeded 라는 함수를 호출해서 해당 key가 expire 되었다면 삭제합니다.
/* This function is called when we are going to perform some operation
* in a given key, but such key may be already logically expired even if
* it still exists in the database. The main way this function is called
* is via lookupKey*() family of functions.
*
* The behavior of the function depends on the replication role of the
* instance, because by default replicas do not delete expired keys. They
* wait for DELs from the master for consistency matters. However even
* replicas will try to have a coherent return value for the function,
* so that read commands executed in the replica side will be able to
* behave like if the key is expired even if still present (because the
* master has yet to propagate the DEL).
*
* In masters as a side effect of finding a key which is expired, such
* key will be evicted from the database. Also this may trigger the
* propagation of a DEL/UNLINK command in AOF / replication stream.
*
* On replicas, this function does not delete expired keys by default, but
* it still returns 1 if the key is logically expired. To force deletion
* of logically expired keys even on replicas, use the EXPIRE_FORCE_DELETE_EXPIRED
* flag. Note though that if the current client is executing
* replicated commands from the master, keys are never considered expired.
*
* On the other hand, if you just want expiration check, but need to avoid
* the actual key deletion and propagation of the deletion, use the
* EXPIRE_AVOID_DELETE_EXPIRED flag.
*
* The return value of the function is 0 if the key is still valid,
* otherwise the function returns 1 if the key is expired. */
int expireIfNeeded(redisDb *db, robj *key, int flags) {
if (server.lazy_expire_disabled) return 0;
if (!keyIsExpired(db,key)) return 0;
/* If we are running in the context of a replica, instead of
* evicting the expired key from the database, we return ASAP:
* the replica key expiration is controlled by the master that will
* send us synthesized DEL operations for expired keys. The
* exception is when write operations are performed on writable
* replicas.
*
* Still we try to return the right information to the caller,
* that is, 0 if we think the key should be still valid, 1 if
* we think the key is expired at this time.
*
* When replicating commands from the master, keys are never considered
* expired. */
if (server.masterhost != NULL) {
if (server.current_client == server.master) return 0;
if (!(flags & EXPIRE_FORCE_DELETE_EXPIRED)) return 1;
}
/* In some cases we're explicitly instructed to return an indication of a
* missing key without actually deleting it, even on masters. */
if (flags & EXPIRE_AVOID_DELETE_EXPIRED)
return 1;
/* If 'expire' action is paused, for whatever reason, then don't expire any key.
* Typically, at the end of the pause we will properly expire the key OR we
* will have failed over and the new primary will send us the expire. */
if (isPausedActionsWithUpdate(PAUSE_ACTION_EXPIRE)) return 1;
/* Delete the key */
deleteExpiredKeyAndPropagate(db,key);
return 1;
}
이제 두번째 케이스입니다.(명령을 수행하지 않고 이벤트가 발생하는 Tick 마다 적당량씩 삭제한다.)
Redis 에는 특정시간마다 serverCron 이라는 함수가 호출이 되고 여기서 필요한 작업들을 수행하게 됩니다. 참고로 특정 지표수집들도 이때 이루어집니다.
/* This is our timer interrupt, called server.hz times per second.
* Here is where we do a number of things that need to be done asynchronously.
* For instance:
*
* - Active expired keys collection (it is also performed in a lazy way on
* lookup).
* - Software watchdog.
* - Update some statistic.
* - Incremental rehashing of the DBs hash tables.
* - Triggering BGSAVE / AOF rewrite, and handling of terminated children.
* - Clients timeout of different kinds.
* - Replication reconnection.
* - Many more...
*
* Everything directly called here will be called server.hz times per second,
* so in order to throttle execution of things we want to do less frequently
* a macro is used: run_with_period(milliseconds) { .... }
*/
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
int j;
UNUSED(eventLoop);
UNUSED(id);
UNUSED(clientData);
/* Software watchdog: deliver the SIGALRM that will reach the signal
* handler if we don't return here fast enough. */
if (server.watchdog_period) watchdogScheduleSignal(server.watchdog_period);
server.hz = server.config_hz;
/* Adapt the server.hz value to the number of configured clients. If we have
* many clients, we want to call serverCron() with an higher frequency. */
if (server.dynamic_hz) {
while (listLength(server.clients) / server.hz >
MAX_CLIENTS_PER_CLOCK_TICK)
{
server.hz *= 2;
if (server.hz > CONFIG_MAX_HZ) {
server.hz = CONFIG_MAX_HZ;
break;
}
}
}
/* for debug purposes: skip actual cron work if pause_cron is on */
if (server.pause_cron) return 1000/server.hz;
run_with_period(100) {
long long stat_net_input_bytes, stat_net_output_bytes;
long long stat_net_repl_input_bytes, stat_net_repl_output_bytes;
atomicGet(server.stat_net_input_bytes, stat_net_input_bytes);
atomicGet(server.stat_net_output_bytes, stat_net_output_bytes);
atomicGet(server.stat_net_repl_input_bytes, stat_net_repl_input_bytes);
atomicGet(server.stat_net_repl_output_bytes, stat_net_repl_output_bytes);
trackInstantaneousMetric(STATS_METRIC_COMMAND,server.stat_numcommands);
trackInstantaneousMetric(STATS_METRIC_NET_INPUT,
stat_net_input_bytes + stat_net_repl_input_bytes);
trackInstantaneousMetric(STATS_METRIC_NET_OUTPUT,
stat_net_output_bytes + stat_net_repl_output_bytes);
trackInstantaneousMetric(STATS_METRIC_NET_INPUT_REPLICATION,
stat_net_repl_input_bytes);
trackInstantaneousMetric(STATS_METRIC_NET_OUTPUT_REPLICATION,
stat_net_repl_output_bytes);
}
/* We have just LRU_BITS bits per object for LRU information.
* So we use an (eventually wrapping) LRU clock.
*
* Note that even if the counter wraps it's not a big problem,
* everything will still work but some object will appear younger
* to Redis. However for this to happen a given object should never be
* touched for all the time needed to the counter to wrap, which is
* not likely.
*
* Note that you can change the resolution altering the
* LRU_CLOCK_RESOLUTION define. */
unsigned int lruclock = getLRUClock();
atomicSet(server.lruclock,lruclock);
cronUpdateMemoryStats();
/* We received a SIGTERM or SIGINT, shutting down here in a safe way, as it is
* not ok doing so inside the signal handler. */
if (server.shutdown_asap && !isShutdownInitiated()) {
int shutdownFlags = SHUTDOWN_NOFLAGS;
if (server.last_sig_received == SIGINT && server.shutdown_on_sigint)
shutdownFlags = server.shutdown_on_sigint;
else if (server.last_sig_received == SIGTERM && server.shutdown_on_sigterm)
shutdownFlags = server.shutdown_on_sigterm;
if (prepareForShutdown(shutdownFlags) == C_OK) exit(0);
} else if (isShutdownInitiated()) {
if (server.mstime >= server.shutdown_mstime || isReadyToShutdown()) {
if (finishShutdown() == C_OK) exit(0);
/* Shutdown failed. Continue running. An error has been logged. */
}
}
/* Show some info about non-empty databases */
if (server.verbosity <= LL_VERBOSE) {
run_with_period(5000) {
for (j = 0; j < server.dbnum; j++) {
long long size, used, vkeys;
size = dictSlots(server.db[j].dict);
used = dictSize(server.db[j].dict);
vkeys = dictSize(server.db[j].expires);
if (used || vkeys) {
serverLog(LL_VERBOSE,"DB %d: %lld keys (%lld volatile) in %lld slots HT.",j,used,vkeys,size);
}
}
}
}
/* Show information about connected clients */
if (!server.sentinel_mode) {
run_with_period(5000) {
serverLog(LL_DEBUG,
"%lu clients connected (%lu replicas), %zu bytes in use",
listLength(server.clients)-listLength(server.slaves),
listLength(server.slaves),
zmalloc_used_memory());
}
}
/* We need to do a few operations on clients asynchronously. */
clientsCron();
/* Handle background operations on Redis databases. */
databasesCron();
/* Start a scheduled AOF rewrite if this was requested by the user while
* a BGSAVE was in progress. */
if (!hasActiveChildProcess() &&
server.aof_rewrite_scheduled &&
!aofRewriteLimited())
{
rewriteAppendOnlyFileBackground();
}
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* If there is not a background saving/rewrite in progress check if
* we have to save/rewrite now. */
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
/* Save if we reached the given amount of changes,
* the given amount of seconds, and if the latest bgsave was
* successful or if, in case of an error, at least
* CONFIG_BGSAVE_RETRY_DELAY seconds already elapsed. */
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
rdbSaveBackground(SLAVE_REQ_NONE,server.rdb_filename,rsiptr);
break;
}
}
/* Trigger an AOF rewrite if needed. */
if (server.aof_state == AOF_ON &&
!hasActiveChildProcess() &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc && !aofRewriteLimited()) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
/* Just for the sake of defensive programming, to avoid forgetting to
* call this function when needed. */
updateDictResizePolicy();
/* AOF postponed flush: Try at every cron cycle if the slow fsync
* completed. */
if ((server.aof_state == AOF_ON || server.aof_state == AOF_WAIT_REWRITE) &&
server.aof_flush_postponed_start)
{
flushAppendOnlyFile(0);
}
/* AOF write errors: in this case we have a buffer to flush as well and
* clear the AOF error in case of success to make the DB writable again,
* however to try every second is enough in case of 'hz' is set to
* a higher frequency. */
run_with_period(1000) {
if ((server.aof_state == AOF_ON || server.aof_state == AOF_WAIT_REWRITE) &&
server.aof_last_write_status == C_ERR)
{
flushAppendOnlyFile(0);
}
}
/* Clear the paused actions state if needed. */
updatePausedActions();
/* Replication cron function -- used to reconnect to master,
* detect transfer failures, start background RDB transfers and so forth.
*
* If Redis is trying to failover then run the replication cron faster so
* progress on the handshake happens more quickly. */
if (server.failover_state != NO_FAILOVER) {
run_with_period(100) replicationCron();
} else {
run_with_period(1000) replicationCron();
}
/* Run the Redis Cluster cron. */
run_with_period(100) {
if (server.cluster_enabled) clusterCron();
}
/* Run the Sentinel timer if we are in sentinel mode. */
if (server.sentinel_mode) sentinelTimer();
/* Cleanup expired MIGRATE cached sockets. */
run_with_period(1000) {
migrateCloseTimedoutSockets();
}
/* Stop the I/O threads if we don't have enough pending work. */
stopThreadedIOIfNeeded();
/* Resize tracking keys table if needed. This is also done at every
* command execution, but we want to be sure that if the last command
* executed changes the value via CONFIG SET, the server will perform
* the operation even if completely idle. */
if (server.tracking_clients) trackingLimitUsedSlots();
/* Start a scheduled BGSAVE if the corresponding flag is set. This is
* useful when we are forced to postpone a BGSAVE because an AOF
* rewrite is in progress.
*
* Note: this code must be after the replicationCron() call above so
* make sure when refactoring this file to keep this order. This is useful
* because we want to give priority to RDB savings for replication. */
if (!hasActiveChildProcess() &&
server.rdb_bgsave_scheduled &&
(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
if (rdbSaveBackground(SLAVE_REQ_NONE,server.rdb_filename,rsiptr) == C_OK)
server.rdb_bgsave_scheduled = 0;
}
run_with_period(100) {
if (moduleCount()) modulesCron();
}
/* Fire the cron loop modules event. */
RedisModuleCronLoopV1 ei = {REDISMODULE_CRON_LOOP_VERSION,server.hz};
moduleFireServerEvent(REDISMODULE_EVENT_CRON_LOOP,
0,
&ei);
server.cronloops++;
return 1000/server.hz;
}
그리고 위의 serverCron 에 있는 함수 중에 databaseCron 이라는 함수가 실제로 메모리 해제를 하게 됩니다. databaseCron 에서는 Expire를 제거하거나, 메모리 Fragmentation 을 줄인다거나 db의 rehashing 등을 통해서 메모리 효율을 높이고 좀 더 빠르게 데이터를 찾게 하기 위한 선처리를 한다고 보면 될듯합니다.
/* This function handles 'background' operations we are required to do
* incrementally in Redis databases, such as active key expiring, resizing,
* rehashing. */
void databasesCron(void) {
/* Expire keys by random sampling. Not required for slaves
* as master will synthesize DELs for us. */
if (server.active_expire_enabled) {
if (iAmMaster()) {
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);
} else {
expireSlaveKeys();
}
}
/* Defrag keys gradually. */
activeDefragCycle();
/* Perform hash tables rehashing if needed, but only if there are no
* other processes saving the DB on disk. Otherwise rehashing is bad
* as will cause a lot of copy-on-write of memory pages. */
if (!hasActiveChildProcess()) {
/* We use global counters so if we stop the computation at a given
* DB we'll be able to start from the successive in the next
* cron loop iteration. */
static unsigned int resize_db = 0;
static unsigned int rehash_db = 0;
int dbs_per_call = CRON_DBS_PER_CALL;
int j;
/* Don't test more DBs than we have. */
if (dbs_per_call > server.dbnum) dbs_per_call = server.dbnum;
/* Resize */
for (j = 0; j < dbs_per_call; j++) {
tryResizeHashTables(resize_db % server.dbnum);
resize_db++;
}
/* Rehash */
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
int work_done = incrementallyRehash(rehash_db);
if (work_done) {
/* If the function did some work, stop here, we'll do
* more at the next cron loop. */
break;
} else {
/* If this db didn't need rehash, we'll try the next one. */
rehash_db++;
rehash_db %= server.dbnum;
}
}
}
}
}
여기서 activeExpireCycle 함수에서 말 그대로 Expire를 처리하게 됩니다.
/* Try to expire a few timed out keys. The algorithm used is adaptive and
* will use few CPU cycles if there are few expiring keys, otherwise
* it will get more aggressive to avoid that too much memory is used by
* keys that can be removed from the keyspace.
*
* Every expire cycle tests multiple databases: the next call will start
* again from the next db. No more than CRON_DBS_PER_CALL databases are
* tested at every iteration.
*
* The function can perform more or less work, depending on the "type"
* argument. It can execute a "fast cycle" or a "slow cycle". The slow
* cycle is the main way we collect expired cycles: this happens with
* the "server.hz" frequency (usually 10 hertz).
*
* However the slow cycle can exit for timeout, since it used too much time.
* For this reason the function is also invoked to perform a fast cycle
* at every event loop cycle, in the beforeSleep() function. The fast cycle
* will try to perform less work, but will do it much more often.
*
* The following are the details of the two expire cycles and their stop
* conditions:
*
* If type is ACTIVE_EXPIRE_CYCLE_FAST the function will try to run a
* "fast" expire cycle that takes no longer than ACTIVE_EXPIRE_CYCLE_FAST_DURATION
* microseconds, and is not repeated again before the same amount of time.
* The cycle will also refuse to run at all if the latest slow cycle did not
* terminate because of a time limit condition.
*
* If type is ACTIVE_EXPIRE_CYCLE_SLOW, that normal expire cycle is
* executed, where the time limit is a percentage of the REDIS_HZ period
* as specified by the ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC define. In the
* fast cycle, the check of every database is interrupted once the number
* of already expired keys in the database is estimated to be lower than
* a given percentage, in order to avoid doing too much work to gain too
* little memory.
*
* The configured expire "effort" will modify the baseline parameters in
* order to do more work in both the fast and slow expire cycles.
*/
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which
we do extra efforts. */
void activeExpireCycle(int type) {
/* Adjust the running parameters according to the configured expire
* effort. The default effort is 1, and the maximum configurable effort
* is 10. */
unsigned long
effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
config_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION +
ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort,
config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
2*effort,
config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-
effort;
/* This function has some global state in order to continue the work
* incrementally across calls. */
static unsigned int current_db = 0; /* Next DB to test. */
static int timelimit_exit = 0; /* Time limit hit in previous call? */
static long long last_fast_cycle = 0; /* When last fast cycle ran. */
int j, iteration = 0;
int dbs_per_call = CRON_DBS_PER_CALL;
long long start = ustime(), timelimit, elapsed;
/* If 'expire' action is paused, for whatever reason, then don't expire any key.
* Typically, at the end of the pause we will properly expire the key OR we
* will have failed over and the new primary will send us the expire. */
if (isPausedActionsWithUpdate(PAUSE_ACTION_EXPIRE)) return;
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
/* Don't start a fast cycle if the previous cycle did not exit
* for time limit, unless the percentage of estimated stale keys is
* too high. Also never repeat a fast cycle for the same period
* as the fast cycle total duration itself. */
if (!timelimit_exit &&
server.stat_expired_stale_perc < config_cycle_acceptable_stale)
return;
if (start < last_fast_cycle + (long long)config_cycle_fast_duration*2)
return;
last_fast_cycle = start;
}
/* We usually should test CRON_DBS_PER_CALL per iteration, with
* two exceptions:
*
* 1) Don't test more DBs than we have.
* 2) If last time we hit the time limit, we want to scan all DBs
* in this iteration, as there is work to do in some DB and we don't want
* expired keys to use memory for too much time. */
if (dbs_per_call > server.dbnum || timelimit_exit)
dbs_per_call = server.dbnum;
/* We can use at max 'config_cycle_slow_time_perc' percentage of CPU
* time per iteration. Since this function gets called with a frequency of
* server.hz times per second, the following is the max amount of
* microseconds we can spend in this function. */
timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
timelimit_exit = 0;
if (timelimit <= 0) timelimit = 1;
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = config_cycle_fast_duration; /* in microseconds. */
/* Accumulate some global stats as we expire keys, to have some idea
* about the number of keys that are already logically expired, but still
* existing inside the database. */
long total_sampled = 0;
long total_expired = 0;
/* Try to smoke-out bugs (server.also_propagate should be empty here) */
serverAssert(server.also_propagate.numops == 0);
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
/* Expired and checked in a single loop. */
unsigned long expired, sampled;
redisDb *db = server.db+(current_db % server.dbnum);
/* Increment the DB now so we are sure if we run out of time
* in the current DB we'll restart from the next. This allows to
* distribute the time evenly across DBs. */
current_db++;
/* Continue to expire if at the end of the cycle there are still
* a big percentage of keys to expire, compared to the number of keys
* we scanned. The percentage, stored in config_cycle_acceptable_stale
* is not fixed, but depends on the Redis configured "expire effort". */
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
iteration++;
/* If there is nothing to expire try next DB ASAP. */
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
slots = dictSlots(db->expires);
now = mstime();
/* When there are less than 1% filled slots, sampling the key
* space is expensive, so stop here waiting for better times...
* The dictionary will be resized asap. */
if (slots > DICT_HT_INITIAL_SIZE &&
(num*100/slots < 1)) break;
/* The main collection cycle. Sample random keys among keys
* with an expire set, checking for expired ones. */
expired = 0;
sampled = 0;
ttl_sum = 0;
ttl_samples = 0;
if (num > config_keys_per_loop)
num = config_keys_per_loop;
/* Here we access the low level representation of the hash table
* for speed concerns: this makes this code coupled with dict.c,
* but it hardly changed in ten years.
*
* Note that certain places of the hash table may be empty,
* so we want also a stop condition about the number of
* buckets that we scanned. However scanning for free buckets
* is very fast: we are in the cache line scanning a sequential
* array of NULL pointers, so we can scan a lot more buckets
* than keys in the same time. */
long max_buckets = num*20;
long checked_buckets = 0;
while (sampled < num && checked_buckets < max_buckets) {
for (int table = 0; table < 2; table++) {
if (table == 1 && !dictIsRehashing(db->expires)) break;
unsigned long idx = db->expires_cursor;
idx &= DICTHT_SIZE_MASK(db->expires->ht_size_exp[table]);
dictEntry *de = db->expires->ht_table[table][idx];
long long ttl;
/* Scan the current bucket of the current table. */
checked_buckets++;
while(de) {
/* Get the next entry now since this entry may get
* deleted. */
dictEntry *e = de;
de = de->next;
ttl = dictGetSignedIntegerVal(e)-now;
if (activeExpireCycleTryExpire(db,e,now)) {
expired++;
/* Propagate the DEL command */
postExecutionUnitOperations();
}
if (ttl > 0) {
/* We want the average TTL of keys yet
* not expired. */
ttl_sum += ttl;
ttl_samples++;
}
sampled++;
}
}
db->expires_cursor++;
}
total_expired += expired;
total_sampled += sampled;
/* Update the average TTL stats for this database. */
if (ttl_samples) {
long long avg_ttl = ttl_sum/ttl_samples;
/* Do a simple running average with a few samples.
* We just use the current estimate with a weight of 2%
* and the previous estimate with a weight of 98%. */
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
}
/* We can't block forever here even if there are many keys to
* expire. So after a given amount of milliseconds return to the
* caller waiting for the other active expire cycle. */
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
/* We don't repeat the cycle for the current database if there are
* an acceptable amount of stale keys (logically expired but yet
* not reclaimed). */
} while (sampled == 0 ||
(expired*100/sampled) > config_cycle_acceptable_stale);
}
elapsed = ustime()-start;
server.stat_expire_cycle_time_used += elapsed;
latencyAddSampleIfNeeded("expire-cycle",elapsed/1000);
/* Update our estimate of keys existing but yet to be expired.
* Running average with this sample accounting for 5%. */
double current_perc;
if (total_sampled) {
current_perc = (double)total_expired/total_sampled;
} else
current_perc = 0;
server.stat_expired_stale_perc = (current_perc*0.05)+
(server.stat_expired_stale_perc*0.95);
}
코드가 복잡해보이지만 요약하면, expire key들이 있는 hash_table을 하나씩 스캔해 나가면서 삭제하는 것입니다. 다만 key가 얼마나 있을지 모르기 때문에 시간을 계산하고, 개수를 세서, 지울 개수를 결정합니다. 정리하면 다음과 같은 기준으로 동작합니다.
ACTIVE_EXPIRE_CYCLE_SLOW
정해진 시간(time_limit)만큼 루프를 돈다. 하나의 DB당 정해진 개수를 expire 하면 다음 DB로 이동한다.
ACTIVE_EXPIRE_CYCLE_FAST
type 이 FAST일 때는 time_limit 를 확 줄인다. 나머지는 동일
이제 세 번째 케이스는 메모리가 필요한 시점에 메모리가 부족해서 지우게 되는데, 이 때는 memory-policy를 따라서 삭제하게 됩니다. 이 부분은 performEvictions 함수에서 동작하게 됩니다.
/* Check that memory usage is within the current "maxmemory" limit. If over
* "maxmemory", attempt to free memory by evicting data (if it's safe to do so).
*
* It's possible for Redis to suddenly be significantly over the "maxmemory"
* setting. This can happen if there is a large allocation (like a hash table
* resize) or even if the "maxmemory" setting is manually adjusted. Because of
* this, it's important to evict for a managed period of time - otherwise Redis
* would become unresponsive while evicting.
*
* The goal of this function is to improve the memory situation - not to
* immediately resolve it. In the case that some items have been evicted but
* the "maxmemory" limit has not been achieved, an aeTimeProc will be started
* which will continue to evict items until memory limits are achieved or
* nothing more is evictable.
*
* This should be called before execution of commands. If EVICT_FAIL is
* returned, commands which will result in increased memory usage should be
* rejected.
*
* Returns:
* EVICT_OK - memory is OK or it's not possible to perform evictions now
* EVICT_RUNNING - memory is over the limit, but eviction is still processing
* EVICT_FAIL - memory is over the limit, and there's nothing to evict
* */
int performEvictions(void) {
/* Note, we don't goto update_metrics here because this check skips eviction
* as if it wasn't triggered. it's a fake EVICT_OK. */
if (!isSafeToPerformEvictions()) return EVICT_OK;
int keys_freed = 0;
size_t mem_reported, mem_tofree;
long long mem_freed; /* May be negative */
mstime_t latency, eviction_latency;
long long delta;
int slaves = listLength(server.slaves);
int result = EVICT_FAIL;
if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK) {
result = EVICT_OK;
goto update_metrics;
}
if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION) {
result = EVICT_FAIL; /* We need to free memory, but policy forbids. */
goto update_metrics;
}
unsigned long eviction_time_limit_us = evictionTimeLimitUs();
mem_freed = 0;
latencyStartMonitor(latency);
monotime evictionTimer;
elapsedStart(&evictionTimer);
/* Try to smoke-out bugs (server.also_propagate should be empty here) */
serverAssert(server.also_propagate.numops == 0);
while (mem_freed < (long long)mem_tofree) {
int j, k, i;
static unsigned int next_db = 0;
sds bestkey = NULL;
int bestdbid;
redisDb *db;
dict *dict;
dictEntry *de;
if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL)
{
struct evictionPoolEntry *pool = EvictionPoolLRU;
while (bestkey == NULL) {
unsigned long total_keys = 0, keys;
/* We don't want to make local-db choices when expiring keys,
* so to start populate the eviction pool sampling keys from
* every DB. */
for (i = 0; i < server.dbnum; i++) {
db = server.db+i;
dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ?
db->dict : db->expires;
if ((keys = dictSize(dict)) != 0) {
evictionPoolPopulate(i, dict, db->dict, pool);
total_keys += keys;
}
}
if (!total_keys) break; /* No keys to evict. */
/* Go backward from best to worst element to evict. */
for (k = EVPOOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
bestdbid = pool[k].dbid;
if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {
de = dictFind(server.db[bestdbid].dict,
pool[k].key);
} else {
de = dictFind(server.db[bestdbid].expires,
pool[k].key);
}
/* Remove the entry from the pool. */
if (pool[k].key != pool[k].cached)
sdsfree(pool[k].key);
pool[k].key = NULL;
pool[k].idle = 0;
/* If the key exists, is our pick. Otherwise it is
* a ghost and we need to try the next element. */
if (de) {
bestkey = dictGetKey(de);
break;
} else {
/* Ghost... Iterate again. */
}
}
}
}
/* volatile-random and allkeys-random policy */
else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM)
{
/* When evicting a random key, we try to evict a key for
* each DB, so we use the static 'next_db' variable to
* incrementally visit all DBs. */
for (i = 0; i < server.dbnum; i++) {
j = (++next_db) % server.dbnum;
db = server.db+j;
dict = (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM) ?
db->dict : db->expires;
if (dictSize(dict) != 0) {
de = dictGetRandomKey(dict);
bestkey = dictGetKey(de);
bestdbid = j;
break;
}
}
}
/* Finally remove the selected key. */
if (bestkey) {
db = server.db+bestdbid;
robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
/* We compute the amount of memory freed by db*Delete() alone.
* It is possible that actually the memory needed to propagate
* the DEL in AOF and replication link is greater than the one
* we are freeing removing the key, but we can't account for
* that otherwise we would never exit the loop.
*
* Same for CSC invalidation messages generated by signalModifiedKey.
*
* AOF and Output buffer memory will be freed eventually so
* we only care about memory used by the key space. */
delta = (long long) zmalloc_used_memory();
latencyStartMonitor(eviction_latency);
dbGenericDelete(db,keyobj,server.lazyfree_lazy_eviction,DB_FLAG_KEY_EVICTED);
latencyEndMonitor(eviction_latency);
latencyAddSampleIfNeeded("eviction-del",eviction_latency);
delta -= (long long) zmalloc_used_memory();
mem_freed += delta;
server.stat_evictedkeys++;
signalModifiedKey(NULL,db,keyobj);
notifyKeyspaceEvent(NOTIFY_EVICTED, "evicted",
keyobj, db->id);
propagateDeletion(db,keyobj,server.lazyfree_lazy_eviction);
postExecutionUnitOperations();
decrRefCount(keyobj);
keys_freed++;
if (keys_freed % 16 == 0) {
/* When the memory to free starts to be big enough, we may
* start spending so much time here that is impossible to
* deliver data to the replicas fast enough, so we force the
* transmission here inside the loop. */
if (slaves) flushSlavesOutputBuffers();
/* Normally our stop condition is the ability to release
* a fixed, pre-computed amount of memory. However when we
* are deleting objects in another thread, it's better to
* check, from time to time, if we already reached our target
* memory, since the "mem_freed" amount is computed only
* across the dbAsyncDelete() call, while the thread can
* release the memory all the time. */
if (server.lazyfree_lazy_eviction) {
if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {
break;
}
}
/* After some time, exit the loop early - even if memory limit
* hasn't been reached. If we suddenly need to free a lot of
* memory, don't want to spend too much time here. */
if (elapsedUs(evictionTimer) > eviction_time_limit_us) {
// We still need to free memory - start eviction timer proc
startEvictionTimeProc();
break;
}
}
} else {
goto cant_free; /* nothing to free... */
}
}
/* at this point, the memory is OK, or we have reached the time limit */
result = (isEvictionProcRunning) ? EVICT_RUNNING : EVICT_OK;
cant_free:
if (result == EVICT_FAIL) {
/* At this point, we have run out of evictable items. It's possible
* that some items are being freed in the lazyfree thread. Perform a
* short wait here if such jobs exist, but don't wait long. */
mstime_t lazyfree_latency;
latencyStartMonitor(lazyfree_latency);
while (bioPendingJobsOfType(BIO_LAZY_FREE) &&
elapsedUs(evictionTimer) < eviction_time_limit_us) {
if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK) {
result = EVICT_OK;
break;
}
usleep(eviction_time_limit_us < 1000 ? eviction_time_limit_us : 1000);
}
latencyEndMonitor(lazyfree_latency);
latencyAddSampleIfNeeded("eviction-lazyfree",lazyfree_latency);
}
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("eviction-cycle",latency);
update_metrics:
if (result == EVICT_RUNNING || result == EVICT_FAIL) {
if (server.stat_last_eviction_exceeded_time == 0)
elapsedStart(&server.stat_last_eviction_exceeded_time);
} else if (result == EVICT_OK) {
if (server.stat_last_eviction_exceeded_time != 0) {
server.stat_total_eviction_exceeded_time += elapsedUs(server.stat_last_eviction_exceeded_time);
server.stat_last_eviction_exceeded_time = 0;
}
}
return result;
}
코드 자체는 복잡하지만, 핵심적인 코드는 다음 부분입니다. MAXMEMORY_POLICY에 따라서 그냥 dict 인지 expires 키들만 있는 곳인지가 결정되게 됩니다.
for (i = 0; i < server.dbnum; i++) {
db = server.db+i;
dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ?
db->dict : db->expires;
if ((keys = dictSize(dict)) != 0) {
evictionPoolPopulate(i, dict, db->dict, pool);
total_keys += keys;
}
}
그리고 이 performEvictions 함수는 매 명령이 처리되는 processCommand 함수 안에서 호출이 되게 됩니다.
그러면 메모리 관리가 잘 될거 같지만… 한 가지 문제가 더 남아있습니다. 실제로 Redis를 관리하다 보면, expire로 키가 사라지거나, 심지어 Del 로 많은 key를 지워도 예상한 것보다 메모리 해제가 되지 않는 경우를 경험하게 됩니다. 이것은 Redis가 메모리 관리를 온전히 jemalloc 에 맡기는데, jemalloc 이 메모리 페이지를 할당하고, 언제 반납하는가에 따라서 물리 메모리 사용량이 바뀌기 때문입니다.
간단히 예를 들어 우리가 메모리를 많이 삭제했지만, 연속된 메모리가 아니라서, 4k 페이지나, 더 큰 페이지에 실제로 데이터는 비워졌지만, 페이지는 반납되지 않고, 다음번에는 그 공간보다 더 큰 메모리가 필요해서, 계속 새로운 페이지를 할당 받을 수 있습니다. 이것을 우리는 fragmentation(파편화) 라고 부릅니다. 그래서 실제로 flushall 이나 flushdb로 삭제하면 바로 메모리가 돌아오는 것을 확인할 수 있는데, 그냥은 데이터를 아무리 삭제해도 메모리가 삭제되지 않는 경우가 종종 발생하므로 이에 대한 주의가 필요합니다.
서비스를 개발하다 보면, 결국 Lock 이 필요한 시점이 있습니다. 하나의 Process 레벨에서 사용하 수 있는 Lock 부터, 프로레스 들끼리의 경합을 보장하기 위한 Lock 등 사용할 수 있는 것들이 많습니다.
그런데 서비스 레벨에서 고민하게 되면, 서버가 한 대가 아니라 두 대일 때 부터, 단순한 Lock을 사용할 수 가 없습니다. 다르게 말하면, 여러 대의 서버에서 공유하는 자원에 대해서 Lock 을 보장하기 위해서는 기존 방식은 사용할 수 가 없다라는 것입니다.
결국 Lock 도 여러 대의 서버들이나 분산 자원에서 획득할 수 있어야 하는 거죠. 그런데 이런 경우는 서비스에서 흔히 발생할 수 있습니다. 특정 리소스를 한 번에 한 명만 처리되어야 하는 경우인데, 예를 들면, A라는 고객의 결제가 여러건이 발생할 때, 한 번에 하나씩만 결제 처리를 진행해야 하는 경우입니다.
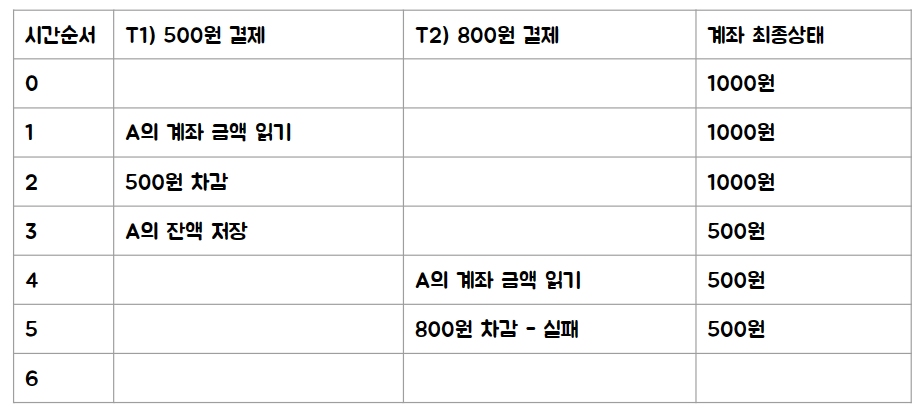
예를 들어 결제 처리가 동시에 일어나게 된다면 다음과 같은 경우가 발생할 수 있습니다. 예를 들어 초기에 1000원이 있는 계좌에 각각 500원 결제와 800원 결제가 발생한다고 가정하겠습니다.
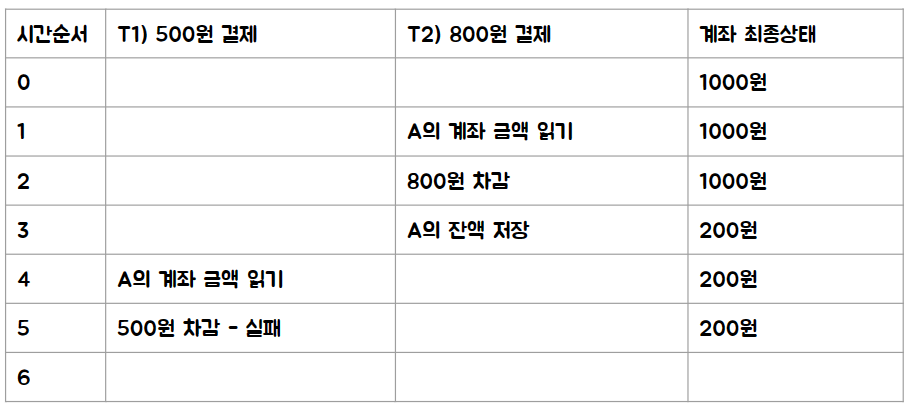
금액이 1000원 뿐이므로 두 개중 하나는 실패해야 하지만, 순서에 따라서 500원 결제가 실패하든, 800원 결제가 실패하든 정상입니다. 다음 두 케이스가 그렇습니다.
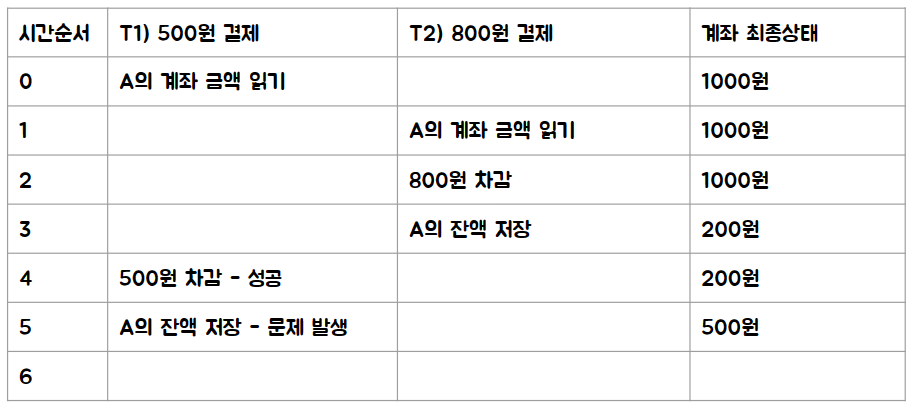
위의 두 케이스는 500원이 남거나 200원이 남는 정상 케이스인데, 문제는 다음과 같은 경우입니다. 결국 1300원이 지불되었지만, 계좌에는 500원이 남아있습니다. 즉 1300원을 쓰고 도리어 200원이 이득이 되는 경우가 되면… 서비스는 문제가 발생합니다.
그래서 이런 문제를 해결하기 위해서 Lock 을 사용해서 각각의 트랜잭션이 각각 처리될 수 있도록 하게 됩니다. (이를 위해서 Lock을 쓰거나, Serialization 을 통해 한번에 하나만 동작하는 것을 보장하거나 할 수 있습니다.)
일단 위의 예를 보면, 그냥 DB Lock 쓰면 안되나요? 라고 물어볼 수 있습니다. 넵 가능합니다. DB Lock 도 가장 쉽게 사용할 수 있는 분산 Lock이라고 볼 수 있습니다. 서비스에서 서버가 여러 대라도 DB는 공유자원으로 대부분 같이 사용하니 실제로 필요한 Row 에 Lock을 건다거나 하는 식으로 DB를 분산 Lock으로 사용이 가능합니다.
그런데 DB는 가장 중요한 공유 자원이기 때문에, 가능하면, 부하를 덜 주는 것이 좋다라고 생각합니다. 이 때 사용하는 것이 Redis 와 같이 좀 더 사용하기 쉽고, 비용 효율적인 공유자원을 분산 Lock으로 사용하는 것입니다. 그래서 여기서는 Redis를 분산 Lock으로 사용하는 사례에 대해서 간단하게 설명해 보려고 합니다.
Redis 를 분산락으로 사용하는 가장 쉬운 방법은 Redis 가 싱글 스레드라는 특성을 이용해서 Lock을 사용하는 방법입니다. 일반적으로 많이 사용하는 방법은 setnx 라는 명령을 사용해서 성공한 경우에 Lock을 획득한다고 가정하는 것입니다.
setnx key:user_1 value
setnx 명령을 이용하면 딱 하나만 해당 Key를 생성할 수 있고, 이미 생성되어 있을 때는 해당 명령이 실패하게 됩니다. 이 특성을 이용해서 분산 Lock으로 이용할 수 있습니다. 그런데 이걸로 Lock으로 쉽게 사용이 가능할까요?
여기서 고민해야 하는 것은 setnx 를 시도했다가 실패하면 어떻게 해야할까요? 비지니스 로직에서 생각한다면, 일반적으로는 Lock 획득을 시도하면, 보통 Lock을 획득해야 다음으로 진행하게 되는데, setnx 는 Key 생성이 실패하면 바로 실패하게 되어버립니다. 그래서 보통 일반적인 형태로 구현하기 위해서는 계속 반복적으로 Lock을 얻기 위한 시도를 해야 합니다.
while:
ok = try setnx("key:user_1")
if ok:
할일()
del key
break
위의 코드를 보면 setnx 에 실패하면 계속 lock을 획득할 때 까지 진행하게 됩니다. 이런 형태를 SpinLock 이라고 부르고 이런형태로 많이 사용하게 됩니다.
그런데 위의 구조로 개발을 한다면 만약에 Lock을 건 프로세서가 장애등으로 해당 Lock을 풀지못하면 어떻게 될까요? 계속 해당 Lock을 획득할 수가 없을 것입니다. 여기서 다시 설정하는 것이 redis의 expire 를 이용해서 key를 특정 시간이 지나면 자동으로 삭제되도록 하는 것입니다.
def lock(key):
ok = setnx(key)
expire(key, 5)
return ok
while:
ok = lock(key)
if ok:
할일()
del key
break
Spinlock 형태는 Lock을 획득할 때 까지 계속 시도를 하기 때문에, 자원을 더 많이 사용하게 됩니다. 그래서 보통 짧은 시간안에 Lock을 획득할 수 있는 케이스에 사용하게 됩니다. 즉, 하나의 작업이 길게 하는 곳에서 이렇게 Lock 을 획득하기 어려운 케이스라면 낭비가 있을 수 있습니다.
그런데 위에서 setnx 로 설명을 했지만, 현재는 Redis에 set 명령에 nx, ex 등의 명령을 추가로 줄 수 있어서, 라이브러리만 지원하면, setnx와 expire 를 동시에 처리할 수 있습니다.
setnx로 설명을 했지만, Redis 에서는 실제로 명령을 한번에 실행되게 해주는 방법들이 있습니다. Lua Script 를 이용하거나, multi/exec 명령을 이용해서 위의 Lock을 설정하는 형태로 할 수 있습니다.
예를 들어 많이 사용하는 Redis Library 중에 Redisson 을 보면 일부 기능은 Lua Script 로 구현하고 있습니다.
Redis를 이용해서 분산 Lock을 쉽게 구현할 수 있지만, 사실 여기서 더 고민할 부분은 Redis 가 장애가 나면 어떻게 될 것인가에 대한 대비를 해둬야 한다는 것입니다. 특히 분산 Lock의 경우, Lock에 문제가 생기면 전체 시스템이 문제가 발생할 수 있기 때문입니다.
직접 구현하셔야 하는 분들은 이런 차이를 이해하시고 개발하시면 될듯 합니다. 여기서 고민을 해보면, 해당 부분이 꼭 실행되어야 하는게 아니라면, 저기서 한번 시도하고, 바로 다른 일로 넘어갈 수도 있습니다. (예를 들어, 해당 결제 이벤트가 큐 기반이라면, 해당 유저가 처리중이면 다시 그냥 Queue에 넣어버리고 다른 유저를 처리할 수도 있습니다.)
slabclass_t 구조체는 다음과 같다. slabclass 에서 list_size 는
slab_list 의 capacity 이다. 그리고 slabs는 현재 몇개의 slab이
할당되었는지는 나타낸다.(현재의 length)
#!c
typedef struct {
unsigned int size; /* sizes of items */
unsigned int perslab; /* how many items per slab */
void *slots; /* list of item ptrs */
unsigned int sl_curr; /* total free items in list */
unsigned int slabs; /* how many slabs were allocated for this class */
void **slab_list; /* array of slab pointers */
unsigned int list_size; /* size of prev array */
size_t requested; /* The number of requested bytes */
} slabclass_t;
memcache 는 시작시에 factor 값에 의해서 사이즈 Range 별로 slabclass id를 가지도록
설정한다. slabs_preallocate 을 이용해서 미리 메모리를 할당해둘 수 도 있다.
이걸 이용하지 않으면 chunk 가 필요할 때 chunk를 할당한다. 기본 chunk size는 1MB이다.
#!c
#define CHUNK_ALIGN_BYTES 8
CHUNK_ALIGN_BYTES = 8
#!c
void slabs_init(const size_t limit, const double factor, const bool prealloc) {
int i = POWER_SMALLEST - 1;
//default chunk_size = 48
//sizeof(item) = 48
//factor = 1.25
//item_size_max = 1024 * 1024
//POWER_SMALLEST = 1
unsigned int size = sizeof(item) + settings.chunk_size;
mem_limit = limit;
if (prealloc) {
/* Allocate everything in a big chunk with malloc */
mem_base = malloc(mem_limit);
if (mem_base != NULL) {
mem_current = mem_base;
mem_avail = mem_limit;
} else {
fprintf(stderr, "Warning: Failed to allocate requested memory in"
" one large chunk.\nWill allocate in smaller chunks\n");
}
}
memset(slabclass, 0, sizeof(slabclass));
while (++i < MAX_NUMBER_OF_SLAB_CLASSES-1 && size <= settings.item_size_max / factor) {
/* Make sure items are always n-byte aligned */
if (size % CHUNK_ALIGN_BYTES)
size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES);
slabclass[i].size = size;
slabclass[i].perslab = settings.item_size_max / slabclass[i].size;
size *= factor;
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n",
i, slabclass[i].size, slabclass[i].perslab);
}
}
power_largest = i;
slabclass[power_largest].size = settings.item_size_max;
slabclass[power_largest].perslab = 1;
if (settings.verbose > 1) {
fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n",
i, slabclass[i].size, slabclass[i].perslab);
}
/* for the test suite: faking of how much we've already malloc'd */
{
char *t_initial_malloc = getenv("T_MEMD_INITIAL_MALLOC");
if (t_initial_malloc) {
mem_malloced = (size_t)atol(t_initial_malloc);
}
}
if (prealloc) {
slabs_preallocate(power_largest);
}
}
slab size 초기화는 다음과 같이 이루어진다. 이 의미는 size가 96까지를 다루는 slabclass
는 그 안에 10922개의 아이템을 저장할 수 있다는 의미이다.
이렇게 만들어진 slabclass 는 slabs_clsid 를 통해서 접근 할 수 있다. 인덱스를
하나씩 증가하면 적절한 크기의 slabclass를 선택한다.
#!c
unsigned int slabs_clsid(const size_t size) {
int res = POWER_SMALLEST;
if (size == 0)
return 0;
while (size > slabclass[res].size)
if (res++ == power_largest) /* won't fit in the biggest slab */
return 0;
return res;
}
slabclass는 item 과도 관계가 있다. 실제 slab_alloc 은 item_alloc 이 호출될때
호출되게 된다.
#!c
typedef unsigned int rel_time_t;
typedef struct _stritem {
/* Protected by LRU locks */
struct _stritem *next;
struct _stritem *prev;
/* Rest are protected by an item lock */
struct _stritem *h_next; /* hash chain next */
rel_time_t time; /* least recent access */
rel_time_t exptime; /* expire time */
int nbytes; /* size of data */
unsigned short refcount;
uint8_t nsuffix; /* length of flags-and-length string */
uint8_t it_flags; /* ITEM_* above */
uint8_t slabs_clsid;/* which slab class we're in */
uint8_t nkey; /* key length, w/terminating null and padding */
/* this odd type prevents type-punning issues when we do
* the little shuffle to save space when not using CAS. */
union {
uint64_t cas;
char end;
} data[];
/* if it_flags & ITEM_CAS we have 8 bytes CAS */
/* then null-terminated key */
/* then " flags length\r\n" (no terminating null) */
/* then data with terminating \r\n (no terminating null; it's binary!) */
} item;
최초 item 할당시에 당연히 slab 도 없기 때문에, do_slabs_newslab()를 호출하게 된다.
SLAB_GLOBAL_PAGE_POOL 는 Reassignment를 위한 것이므로 최초에는 slabclass만 존재하고
내부에 할당된 slab은 없음. get_page_from_global_pool() 에서도 데이터가 없으므로 실제
메모리 할당은 memory_allocate 에 의해서 이루어진다.
할당된 메모리 ptr은 split_slab_page_into_freelist 에 의해서 초기화 된다.
#!c
static void split_slab_page_into_freelist(char *ptr, const unsigned int id) {
slabclass_t *p = &slabclass[id];
int x;
for (x = 0; x < p->perslab; x++) {
do_slabs_free(ptr, 0, id);
ptr += p->size;
}
}
p->size는 slabclass item의 크기이므로 그 값만큼 증가하면서 do_slabs_free 를 호출해서
item을 저장할 수 있는 형태로 정보를 저장한다. ptr 이 p->size 만큼 계속 증가하는데 주목하자.
#!c
static void do_slabs_free(void *ptr, const size_t size, unsigned int id) {
slabclass_t *p;
item *it;
assert(id >= POWER_SMALLEST && id <= power_largest);
if (id < POWER_SMALLEST || id > power_largest)
return;
MEMCACHED_SLABS_FREE(size, id, ptr);
p = &slabclass[id];
it = (item *)ptr;
it->it_flags = ITEM_SLABBED;
it->slabs_clsid = 0;
it->prev = 0;
it->next = p->slots;
if (it->next) it->next->prev = it;
p->slots = it;
p->sl_curr++;
p->requested -= size;
return;
}
p는 slabclass, it는 해당 ptr의 메모리 영역이다. p->slots는 기존에 할당된 item list를
가리키는 포인터이다. 즉 it->next 로 현재의 it->next 에 기존의 item list를 저장하고,
기존의 item list의 prev는 새롭게 추가될 it가 된다. 그리고 다시 p->slots은 it를 가리키게
되므로, linked list로 slabclass에 할당되는 모든 item들이 double linked list 형식으로
저장되게 된다.(실제로 메모리 할당은 item_max_size 형태로 할당되지만… 논리적으로 이어진다.)
위의 정보들을 보면, 여러가지 정보가 있지만, instantaneous_ops_per_sec 이라는 항목처럼 instantaneous_ 라는 접두어로 시작하는 항목들이 있습니다. instantaneous 의 번역을 보면 즉각적인 내용이 보입니다. 즉각적이라 현재 정보만 보여주는 걸까요?
해당 내용을 보게 된 것은 Redis 이전을 고민하는데 네트웍 사용량이 얼마나 되는지를 분석해보고 싶어하는 분이 계셨기 때문입니다. 아래 처럼 input_kbps, output_kbps 등이 보이는데 해당 값이 맞지 않는다는 느낌이었던거죠.
hi :
I want to monitor redis traffic through redis info.But I found instantaneous_input_kbps and instantaneous_output_kbps are not the true traffic about redis.
Instantaneous_input_kbps is smaller than the true traffic.
Is there something wrong?
######################sending data to redis
#network traffic
Time -------------traffic------------
Time bytin bytout pktin pktout
26/02/16-16:30:25 1.2M 310.0K 5.5K 3.9K
26/02/16-16:30:27 1.2M 314.2K 5.5K 3.9K
26/02/16-16:30:29 1.1M 321.5K 5.4K 3.9K
26/02/16-16:30:31 1.2M 313.7K 5.5K 3.9K
26/02/16-16:30:33 1.3M 321.0K 5.6K 4.0K
26/02/16-16:30:35 1.2M 308.2K 5.3K 3.8K
26/02/16-16:30:37 1.2M 308.9K 5.4K 3.8K
####redis info
instantaneous_input_kbps:678.29
instantaneous_output_kbps:4.85
instantaneous_input_kbps:666.07
instantaneous_output_kbps:4.79
instantaneous_input_kbps:676.34
instantaneous_output_kbps:4.85
instantaneous_input_kbps:675.49
instantaneous_output_kbps:4.84
instantaneous_input_kbps:671.42
instantaneous_output_kbps:4.82
instantaneous_input_kbps:667.50
instantaneous_output_kbps:4.80
instantaneous_input_kbps:666.37
instantaneous_output_kbps:4.79
#####################stop sending data
Time -------------traffic------------
Time bytin bytout pktin pktout
26/02/16-16:34:59 157.5K 22.7K 226.00 228.00
26/02/16-16:35:01 159.8K 24.9K 235.00 237.00
26/02/16-16:35:03 208.9K 134.5K 901.00 947.00
26/02/16-16:35:05 133.3K 61.1K 285.00 269.00
^C
##redis info
instantaneous_output_kbps:1.17
instantaneous_input_kbps:0.01
instantaneous_output_kbps:1.17
instantaneous_input_kbps:0.01
instantaneous_output_kbps:1.16
instantaneous_input_kbps:0.01
instantaneous_output_kbps:1.17
instantaneous_input_kbps:0.01
instantaneous_output_kbps:1.17
instantaneous_input_kbps:0.01
instantaneous_output_kbps:1.17
일단 결론부터 말하자면, 앞에 instantaneous 가 붙는 값들은 정확한 값이 아니라 샘플링을 통해서 몇개씩 저장해서 확인하는 값입니다. 계속 기록되고 있는게 아니라, 순간 순간의 값들을 샘플링해서 이에 대한 정보를 보여줍니다.
일단 해당 정보를 가져오는 것을 확인해 봅시다.
info 함수를 만드는 곳을 보면 다음과 같이 가져오고 있습니다. 해당 정보를 가져오는 곳을 보면 아래와 같이 getInstantaneousMetric 함수를 통해서 정보를 가져오고 있습니다.
getInstantaneousMetric(STATS_METRIC_COMMAND)
그리고 해당 함수를 가보면 다음과 같이 간단하게 구현되어 있습니다.
/* Return the mean of all the samples. */
long long getInstantaneousMetric(int metric) {
int j;
long long sum = 0;
for (j = 0; j < STATS_METRIC_SAMPLES; j++)
sum += server.inst_metric[metric].samples[j];
return sum / STATS_METRIC_SAMPLES;
}
코드를 보면 server.inst_metric[metric]./samples[j] 값을 가져와서 sum을 한 다음에 평균을 만들어서 전달하고 있습니다. 이제 그럼 저 server.inst_metric 값을 저장하는 곳을 확인해 봅시다.
크게 이동 하지 않고 바로 위에 trackInstantaneousMetric 라는 함수가 있습니다.
/* Add a sample to the operations per second array of samples. */
void trackInstantaneousMetric(int metric, long long current_reading) {
long long now = mstime();
long long t = now - server.inst_metric[metric].last_sample_time;
long long ops = current_reading -
server.inst_metric[metric].last_sample_count;
long long ops_sec;
ops_sec = t > 0 ? (ops*1000/t) : 0;
server.inst_metric[metric].samples[server.inst_metric[metric].idx] =
ops_sec;
server.inst_metric[metric].idx++;
server.inst_metric[metric].idx %= STATS_METRIC_SAMPLES;
server.inst_metric[metric].last_sample_time = now;
server.inst_metric[metric].last_sample_count = current_reading;
}
redis 는 매 Tick 마다 serverCron 이라는 작업을 호출합니다. 그리고 그 안에 매 100ms 마다. 아래와 같이 sampling 정보를 저장합니다.
run_with_period(100) {
long long stat_net_input_bytes, stat_net_output_bytes;
long long stat_net_repl_input_bytes, stat_net_repl_output_bytes;
atomicGet(server.stat_net_input_bytes, stat_net_input_bytes);
atomicGet(server.stat_net_output_bytes, stat_net_output_bytes);
atomicGet(server.stat_net_repl_input_bytes, stat_net_repl_input_bytes);
atomicGet(server.stat_net_repl_output_bytes, stat_net_repl_output_bytes);
trackInstantaneousMetric(STATS_METRIC_COMMAND,server.stat_numcommands);
trackInstantaneousMetric(STATS_METRIC_NET_INPUT,
stat_net_input_bytes + stat_net_repl_input_bytes);
trackInstantaneousMetric(STATS_METRIC_NET_OUTPUT,
stat_net_output_bytes + stat_net_repl_output_bytes);
trackInstantaneousMetric(STATS_METRIC_NET_INPUT_REPLICATION,
stat_net_repl_input_bytes);
trackInstantaneousMetric(STATS_METRIC_NET_OUTPUT_REPLICATION,
stat_net_repl_output_bytes);
}
여기서 볼 것은 Sampling 방식입니다. network에서 packet 을 읽거나 쓸 때마다 stat_net_input_bytes 나 stat_net_output_bytes 값이 증가하게 되고, 해당 시점을 값을 100ms 마다 저장해서 이 값의 차이를 Sample 로 저장하게 됩니다.
예를 들어, stat_net_input_bytes 는 readQueryFromClient 함수안에서 다음과 같이 패킷을 읽을 때 마다 증가하게 됩니다.
최근에 우연히 아는 분의 글을 보다가 갑자기 궁금함이 생겼습니다. 네이버 클라우드의 Redis를 사용중인데 CacheEvict 에서 allEntries = true 를 줬을 경우, 동작이 실패한다는 것이었습니다. Spring에서 Cache를 쉽게 제공하는 방법중에 @Cacheable, @CachePut @CacheEvict 를 제공합니다. (물론 저는 이걸 잘 모르지만…) 그 중에 Cache를 정리할 때 사용하는 CacheEvict 은 allEntries 라는 옵션이 있는데 이게 true가 되면 어떻게 동작할까? 라는 의문이었습니다. (일단 실무에서는 사용하지 않는 것이 좋은 옵션으로 보입니다.)
여기서 먼저 Evict 에 대해서는 Cache 자체를 지운다는 의미보다는, 메모리가 부족해서 더 이상 캐시할 수 없을 때, 메모리를 확보하기 위해서, 기존 캐시된 데이터를 지우는 것을 의미합니다.
그런데 저도 저 옵션을 본 기억도 없고(정말인가~~~~) 저게 뜨면 어떻게 되지라는 게 궁금해서 일단 잠시 살펴보게 되었습니다. 먼저 CacheEvict.java 는 다음과 같이 구성되어 있습니다. 일단 주석은 다 지웁니다.
보시면 아시겠지만 allEntries() 는 boolean 형태의 정보를 저장하고 있습니다. 그런데 사실 우리가 알아보고자 하는 부분은 Redis에서 어떻게 동작하는 가 이므로, spring-data-redis 에서 어떻게 동작하는지를 알아야 합니다.
그런데 spring-data-redis에서는 allEntries 라는 정보를 확인하는 부분이 없습니다. 이 이야기는 결국 뭔가 다른 변수로 전환된다는 것이죠. 그래서 spring-framework 에서 allEntries 를 검색해봅니다. 다른 부분은 전부 사용하는 곳인데 다음과 같은 코드가 발견이 됩니다.
이제 cacheWide로 한번 검색해봅니다. spring-context/src/main/java/org/springframework/cache/interceptor/CacheEvictOperation.java 라는 파일에서 다음과 같은 코드를 사용합니다. 아래 코드를 보면 이제 내부에서는 아마도 isCacheWide 라는 함수로 사용이 될꺼라고 예상이 됩니다.
public boolean isCacheWide() {
return this.cacheWide;
}
isCacheWide() 함수를 호출하는 곳이 한 군데 밖에 없다는 것을 확인할 수 있습니다.
spring-context/src/main/java/org/springframework/cache/interceptor/CacheAspectSupport.java 를 살펴봅니다. performCacheEvict() 라는 메서드에서 isCacheWide 면 doClear 를, 그렇지 않으면 doEvict 을 호출합니다.
doClear() 함수는 spring-context/src/main/java/org/springframework/cache/interceptor/AbstractCacheInvoker.java 에 구현되어 있습니다.
/**
* Execute {@link Cache#evict(Object)}/{@link Cache#evictIfPresent(Object)} on the
* specified {@link Cache} and invoke the error handler if an exception occurs.
*/
protected void doEvict(Cache cache, Object key, boolean immediate) {
try {
if (immediate) {
cache.evictIfPresent(key);
}
else {
cache.evict(key);
}
}
catch (RuntimeException ex) {
getErrorHandler().handleCacheEvictError(ex, cache, key);
}
}
/**
* Execute {@link Cache#clear()} on the specified {@link Cache} and
* invoke the error handler if an exception occurs.
*/
protected void doClear(Cache cache, boolean immediate) {
try {
if (immediate) {
cache.invalidate();
}
else {
cache.clear();
}
}
catch (RuntimeException ex) {
getErrorHandler().handleCacheClearError(ex, cache);
}
}
이제 호출되는 것은 Cache 구조체라는 것을 알 수 있습니다. cache.invalidate() 거나 cache.clear() 거나…(아마도 cache.clear()겠죠? – 반전은 실제로는 둘다 cache.clear() 입니다.)
그런데 Cache 는 그냥 인터페이스 입니다.
public interface Cache {
String getName();
Object getNativeCache();
@Nullable
ValueWrapper get(Object key);
@Nullable
<T> T get(Object key, @Nullable Class<T> type);
@Nullable
<T> T get(Object key, Callable<T> valueLoader);
void put(Object key, @Nullable Object value);
@Nullable
default ValueWrapper putIfAbsent(Object key, @Nullable Object value) {
ValueWrapper existingValue = get(key);
if (existingValue == null) {
put(key, value);
}
return existingValue;
}
void evict(Object key);
default boolean evictIfPresent(Object key) {
evict(key);
return false;
}
void clear();
interface ValueWrapper {
@Nullable
Object get();
}
@SuppressWarnings("serial")
class ValueRetrievalException extends RuntimeException {
@Nullable
private final Object key;
public ValueRetrievalException(@Nullable Object key, Callable<?> loader, Throwable ex) {
super(String.format("Value for key '%s' could not be loaded using '%s'", key, loader), ex);
this.key = key;
}
@Nullable
public Object getKey() {
return this.key;
}
}
}
검색해보면 spring-framework 안에도 Cache를 구현한 클래스가 몇 개 있습니다.
AbstractValueAdaptingCache
NoOpCache
TransactionAwareCacheDecorator
spring-data-redis 코드를 보면 바로 Cache Interface 를 구현한 클래스는 없고 발견된 RedisCache 가 AbstractValueAdaptingCache 를 확장해서 구현하고 있습니다.
저는 역으로 ./src/main/java/org/springframework/data/redis/cache/RedisCache.java 라는 파일을 찾아서(이름에 Cache가 있는 파일을) 찾아서 확인을 해보니 AbstractValueAdaptingCache 를 사용하고 있는 것을 볼 수 있습니다.
public class RedisCache extends AbstractValueAdaptingCache {
private static final byte[] BINARY_NULL_VALUE = RedisSerializer.java().serialize(NullValue.INSTANCE);
private final String name;
private final RedisCacheWriter cacheWriter;
private final RedisCacheConfiguration cacheConfig;
private final ConversionService conversionService;
protected RedisCache(String name, RedisCacheWriter cacheWriter, RedisCacheConfiguration cacheConfig) {
super(cacheConfig.getAllowCacheNullValues());
Assert.notNull(name, "Name must not be null!");
Assert.notNull(cacheWriter, "CacheWriter must not be null!");
Assert.notNull(cacheConfig, "CacheConfig must not be null!");
this.name = name;
this.cacheWriter = cacheWriter;
this.cacheConfig = cacheConfig;
this.conversionService = cacheConfig.getConversionService();
}
......
@Override
public void clear() {
byte[] pattern = conversionService.convert(createCacheKey("*"), byte[].class);
cacheWriter.clean(name, pattern);
}
......
}
CacheWriter 의 clean을 호출 하는 것을 볼 수 있습니다. 다만 위의 pattern 을 잘 기억해야 합니다. 결국 “*” 를 가져옵니다. CacheWriter 는 RedisCacheWriter 입니다.
RedisCache 에서 RedisCacheWriter 는 생성되면서 전달 받게 됩니다. 해당 클래스를 구현할 클래스를 찾아보도록 하겠습니다. Spring-data-redis 에서는 RedisCacheWriter 를 구현한 클래스는 DefaultRedisCacheWriter 하나 뿐입니다.
class DefaultRedisCacheWriter implements RedisCacheWriter {
private final RedisConnectionFactory connectionFactory;
private final Duration sleepTime;
private final CacheStatisticsCollector statistics;
private final BatchStrategy batchStrategy;
......
@Override
public void clean(String name, byte[] pattern) {
Assert.notNull(name, "Name must not be null!");
Assert.notNull(pattern, "Pattern must not be null!");
execute(name, connection -> {
boolean wasLocked = false;
try {
if (isLockingCacheWriter()) {
doLock(name, connection);
wasLocked = true;
}
long deleteCount = batchStrategy.cleanCache(connection, name, pattern);
while (deleteCount > Integer.MAX_VALUE) {
statistics.incDeletesBy(name, Integer.MAX_VALUE);
deleteCount -= Integer.MAX_VALUE;
}
statistics.incDeletesBy(name, (int) deleteCount);
} finally {
if (wasLocked && isLockingCacheWriter()) {
doUnlock(name, connection);
}
}
return "OK";
});
}
......
}
이제 거의 다 온거 같습니다. batchStrategy.cleanCache() 를 호출하고 있습니다. BatchStrategy 역시 interface 입니다. ./src/main/java/org/springframework/data/redis/cache/BatchStrategy.java 에서 볼 수 있습니다.
public interface BatchStrategy {
/**
* Remove all keys following the given pattern.
*
* @param connection the connection to use. Must not be {@literal null}.
* @param name The cache name. Must not be {@literal null}.
* @param pattern The pattern for the keys to remove. Must not be {@literal null}.
* @return number of removed keys.
*/
long cleanCache(RedisConnection connection, String name, byte[] pattern);
}
이제 BatchStrategy를 구현한 클래스를 살펴봅시다. 모두 src/main/java/org/springframework/data/redis/cache/BatchStrategies.java 에 존재하고 있습니다. 여기에는 두 개의 구현체가 존재하는 데 첫번째가 Keys 입니다. 보시면 cleanCache에서 아까 pattern (여기서는 “*” 이 전달되었습니다.) keys 명령을 통해서 패턴을 모두 가져오고 이걸 connection의 del 로 삭제하게 됩니다. 즉 Keys 를 쓰면 전부 지워집니다.
static class Keys implements BatchStrategy {
static Keys INSTANCE = new Keys();
@Override
public long cleanCache(RedisConnection connection, String name, byte[] pattern) {
byte[][] keys = Optional.ofNullable(connection.keys(pattern)).orElse(Collections.emptySet())
.toArray(new byte[0][]);
if (keys.length > 0) {
connection.del(keys);
}
return keys.length;
}
}
두 번째 클래스는 Scan 입니다. Scan 명령을 통해서 Key를 전부 가져와서 다시 connection 의 del 을 통해서 다 지우게 됩니다.
static class Scan implements BatchStrategy {
private final int batchSize;
Scan(int batchSize) {
this.batchSize = batchSize;
}
@Override
public long cleanCache(RedisConnection connection, String name, byte[] pattern) {
Cursor<byte[]> cursor = connection.scan(ScanOptions.scanOptions().count(batchSize).match(pattern).build());
long count = 0;
PartitionIterator<byte[]> partitions = new PartitionIterator<>(cursor, batchSize);
while (partitions.hasNext()) {
List<byte[]> keys = partitions.next();
count += keys.size();
if (keys.size() > 0) {
connection.del(keys.toArray(new byte[0][]));
}
}
return count;
}
}
일단 코드를 살펴본 대로면 FlushAll, FlushDB의 이슈는 아니므로 KEYS가 막혀있는 것이 문제일 수 있습니다. 그렇다면 어떻게 회피하면 될까요? 아까 BatchStrategy 가 KEYS와 Scan 두 가지 였습니다. 만약에 KEYS가 안된다면 Scan 을 쓰면 되지 않을까요?(기본적으로 Scan이 Default 값이긴 합니다.)
보통 위와 같은 형태로 RedisCacheManager 를 구현하게 되는데, 코드를 보면 위의 RedisCacheManager.RedisCacheManagerBuilder.fromConnectionFactory() 함수는 다음과 같이 구현되어 있습니다.(src/main/java/org/springframework/data/redis/cache/RedisCacheManager.java)
public static RedisCacheManagerBuilder fromConnectionFactory(RedisConnectionFactory connectionFactory) {
Assert.notNull(connectionFactory, "ConnectionFactory must not be null!");
return new RedisCacheManagerBuilder(RedisCacheWriter.nonLockingRedisCacheWriter(connectionFactory));
}
보시면 RedisCacheWriter.nonLockingRedisCacheWriter 를 그냥 호출하고 있습니다. 이제 해당 코드를 살펴봅시다. src/main/java/org/springframework/data/redis/cache/RedisCacheWriter.java 의 nonLockingRedisCacheWriter 를 보면 그렇습니다. 다음과 같이 keys가 그냥 default 네요. 이래서 KEYS 명령이 막혀 있어서 동작하지 않는 것입니다.