가끔씩 Redis 가 뭐예요? Memcached 가 뭐예요? 또는 Cache를 왜 써요? 라는 저도 모르는 근원적인 질문을 받을 때가 있습니다.
일단 그 근원적인 질문에 답하기 위해서는 먼저 Cache 란 무엇인가로 부터 시작해야 될것 같습니다. 일단 Cache는 “많은 시간이나 연산이 필요한 일에 대한 결과를 저장해 두는 것” 이라고 할 수 있습니다. 우리가 1 부터 100까지 결과를 더하는 것은 5050 이라고 아주 쉽게 계산할 수 도 있지만…(가우스 천재 녀석…) 보통은 1 부터 100 까지 종에 적어서 결과를 구하는 아주 어려운 방식을 택하게 됩니다. 마치 아래의 경우를 수를 찾는 것 처럼요.
실제로 저는 1부터 100 더하기가 파스칼인줄 알았는데, 검색해보니 가우스였습니다. 그런데 1부터 100까지 결과를 계산할 수도 있고, 저처럼 외워둘 수도 있습니다. 가우스라는 걸 찾기 위해서 검색을 해야 하지만, 머릿속에 기억을 해두면, 검색하는 시간을 줄일 수 있습니다. 즉, 결과를 아주 빨리 찾을 수 있습니다.
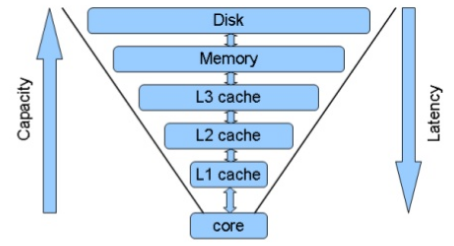
많이들 아시겠지만, 위의 그림을 보면 CPU 에서는 Register가 가장 속도가 빠르고, 그 뒤로 L1 , L2, L3, Memory, Disk 순으로 접근 속도는 느려지고, 용량은 커지고, 비용도 싸집니다. 인터넷 서비스를 생각해 보도록 하죠. 특정 서비스에 로그인 한다고 하면, 유저 정보를 디스크에서 가지고 오면 가장 느릴 것이고, Memory 에 있으면 훨씬 빠를 겁니다. 특히 데이터가 Disk 블럭 하나에 있다면, 하나의 블럭만 읽으면 되지만, 여러 군데 나눠져 있다면… 그 만큼 더 느려지게 되겠죠.
결국 Cache는 빠른 속도를 위해서 사용하게 되는겁니다. 그런데 이런 의문이 생깁니다. 위의 그림을 봐도 점점 용량은 줄어가는데, 모든 데이터를 빠르게 저장할 수 없지 않느냐? 라는 질문이 생기는 거죠.
물론 용량도 충분히 늘릴 수 있습니다. 다만 돈이 많이 들 뿐이죠. 아직 같은 용량일 때 HDD 보다는 SSD 가 더 비싸고, SSD 보다는 메모리가 더 비싸죠. 그래서 “Cache is Cash” 라는 명언도 있습니다. 그러면 Cache 가 과연 유용한가? 라는 질문이 생깁니다. 비용이 너무 비싸기 때문이죠. 그런데… 역시 세상은 파레토의 법칙에 의해서 돌아갑니다. 전체의 80%의 요청이나 부하가 상위 20% 유저로 인해서 발생하는… 다시 그 20%의 80%도 그 안의 20%에 의해서 발생합니다. 그래서, 자주 접근하는 정보만 Cache 하더라도 엄청나게 좋은 효과를 볼 수 있습니다. 다만, 대부분이 생성, 수정, 삭제라면, Cache를 좀 다른 방법으로 이용해야 합니다.(write-back을 찾아보세요.)
위의 Login 사례를 다시 한번 살펴 보도록 하겠습니다. 실제 유저가 id, passwd를 입력하면 다음과 같은 sql 문이 실행된다고 하겠습니다.
select * from Users where id='charsyam';
위의 쿼리가 실행되는 데는 다음과 같은 시간이 듭니다.
- 쿼리를 파싱
- id 가 charsyam 인 데이터를 인덱스에 찾아서 전달, 이를 위해서 Disk 읽기 발생
물론, 데이터베이스도 알아서 캐싱을 하고 있습니다. 다만, 데이터량이 엄청 많으면, 그 디스크에 대한 캐시 확률이 더 떨어지게 되죠.
그런데 Cache를 사용하게 되면, 보통 Key-Value 타입을 사용하게 되면, 쿼리를 파싱하는 시간도 없어지고, 훨씬 접근 속도가 빠른 메모리에서 읽어오게 되기 때문에, 거기서 많은 속도 차이가 나게 됩니다. 다음은 DB 서버의 CPU 사용량입니다. Cache를 적용한 이후부터, 전체적으로 Wait I/O가 많이 떨어지는 것을 볼 수 있습니다.

그리고 두 번째로 DB로 들어오는 쿼리 수입니다.

실제로 Update는 계속 들어와야 하는 작업이므로 변화가 없지만, Select와 Qcache_hits 는 거의 1/10 수준으로 줄어버립니다. DB서버로의 요청이 줄어버려서, 전체 서비스가 좀 더 큰 요청이 들어와도 버틸 수 있게 해줍니다.
그럼 Redis 나 Memcached 같은 Cache 서비스를 사용하는 것은 왜 일까요? 당연히 속도면에서는 각각의 서버의 메모리에 들고 있는 것이 유리합니다. 그런데, 여러 서버에 있는 데이터를 동기화 하는 것은 사실 쉬운 일이 아닙니다. 그리고 데이터량이 많으면, 결국은 한 서버에 둘 수 없어서, 여러 서버로 나뉘어야 합니다.
잘 생각해보면, 서비스의 로직 서버와 DB 서버 역시 별도록 분리되어 있습니다. 각 서버에 DB 서버를 모두 올릴 수도 있는데, 이러면, 각 DB 서버의 동기화가 필요해지겠죠.(물론, 이런식으로 하는 서비스 구조도 있습니다. 주로 읽기만 많은 서비스이며, 그 데이터의 동기화가 덜 중요할 경우…)
그래서 결국 Redis와 Memcached 를 쓰는 것은 위의 여러 가지 장점을 취하기 위해서입니다. 물론 데이터 량이 늘어나면, 이 서버들도 여러 대가 필요해지고, 이를 위해 데이터를 어떻게 찾을 지에 대한 룰도 추가로 필요해지게 됩니다.
이런 류의 좀 더 자세한 내용이 알고 싶으시다면, 제 slideshare를 참고하시면 아주 초급적인 자료들이 있는데, 대표적으로 다음 자료를 추천합니다.
